In this section, the selection of the CH that uses the GA and the KH is discussed.
3.1. CH Selection Using Genetic Algorithm
John Holland first presented the GA in 1970, based on the principle of evolution as outlined by Charles Darwin. This adaptive heuristic technique is used to resolve dynamic issues and is based on genetic evolution. This algorithm was employed for solving several other NP-hard problems, but encoding a problem regarding a particular set of chromosomes in which each chromosome is a clarification is a primary issue in solving a problem with GA. To gauge the chromosomal quality, a fitness function is employed. Operations of crossover and mutation are used in accordance with the fitness value depending on the chosen chromosomes. By means of the concatenation of the elements of both selected chromosomes, new solutions called offspring are generated. For all offspring produced, a mutation is used to change one or more of the genetic elements to avoid the solution from being trapped inside local minima. The recommended CH selection process solutions’ GA is as follows:
Population: This offers numerous different approaches to the issue. The population size will not be directly related to the algorithm’s accuracy. The length of that individual depends on how many nodes are actually present in the network. If a node has a 1 instead of a 0, it is a CH, while a 0 means it is a member node. There is an arbitrary production of the initial population.
Fitness Function: This suggests adaptability. Based on the fitness function, the level of fitness for each person is determined. Regarding the current work, four different parameters are taken into account for this:
- -
The remaining energy;
- -
The number of CHs;
- -
The total intra-cluster communication distance;
- -
The total distance from the CHs to the base station.
As the number of CHs decreases, the distance between the CH and the BS will generally drop but the distance for intra-cluster communication will grow. The preceding two parameter values will be listed first.
This fitness function [
11] has been described as
In this case, N stands for the quantity of already accessible network nodes. The entire distance between the CH and the BS has received additional emphasis, as can be seen in this function.
Selection: In order to create a new population, the approach selects individuals from the existing population. The main goal of employing this selection function for the GA was to give members who were more reproductively fit better chances. Some of the techniques used for the implementation of the process of selection are the random, rank, Boltzmann, tournament, and roulette wheel techniques.
Crossover: The probability of the crossover operation is determined by the rate of crossover, and it occurs between two distinct chromosomes. Both chromosomes that are segregated through the crossover site swap the sections as required.
Mutation: For each chromosome bit, a mutation operator is applied using the probability of mutation rate. The bit of 0 changes to 1 once a mutation is complete.
Table 1 shows a sample working for CH selection using GA.
3.2. Proposed CH Selection Using Dual Krill Herd Optimization Algorithm
An innovative optimization technique that aids in the resolution of extremely complicated problems is the KH. This is based on individual performance and belongs to the family of swarm intelligence. There are three different movements that are implemented, and these are again repeated in the KH. The solution that is the best is considered by the directions of the search. A krill position can be set in one of three ways: The effort exerted by the other krill;
The foraging action;
Physical diffusion.
The KH assumes a Lagrangian model as depicted here:
where
represents the motion of the other krill, Fide notes the new seeking motion, and the physical distribution is
. According to Equation (2), the NP is represented by the variables
i = 1, 2…, and it represents the population’s size.
The initial motion has a target that is local and has a repulsive impact that determines the motion’s direction,
. Equation (3) has been given as follows for the krill
i…
Nmax:
Its maximum attempted speed is indicated by Nmax, ωn is the weight of the inertia, and Nold is the final motion.
The second motion will be determined by food location and earlier experience. In the case of the krill, it may be defined as in the following equations:
where
Vf denotes it looking for speed,
ωf is the inertia weight for the second motion, and
Fold depicts the final motion.
The third motion is an unpredictable process with two distinct components, such as the highest diffusion speed and an unpredictable directional vector. Equation (6) is specified as follows:
where
Dmax denotes the maximum speed flow; a random vector is denoted by δ.
Using three movements, the krill position from t to
t + Δ
t is represented as per Equation (7):
Other krill have an impact on the movement of the KH. Until a pausing condition is met, physical dissemination and foraging will continue for a number of these generations. Inter-cluster communication and intra-cluster communication are two different sorts of communication situations that can occur in a WSN. The work consists of a single-hop approach. Clustering was performed to improve intra-cluster communication and select an appropriate cluster representative from each round of nodes. Data obtained from different member nodes were aggregated at the level of the CH and forwarded to the BS. Through the use of this method, less energy was consumed. Yet, there may be a problem in that the CH is a stationary node and will eventually lose energy.
Therefore, for each round, there is a need to assign a new node to CH. There is a decision made to choose a node that is well suited, and this is taken up by the KH. The energy of the node and that of its separation nodes that are not CH members are used to select a new CH in each round. For operating the protocols of clustering, there are four different phases and two stages. The four phases are as follows: (1) selecting the CH; (2) formation of the clusters; (3) data aggregation; and (4) data communication. Two stages used are the setup state steady-stalemate stage. In this single setup phase, a sensor will transmit another location and its remaining data energy.
Thus, average energy is measured by the BS for every round. CH will be selected for that round based on the highest average energy, provided it is a capable node. This methodology is also further implemented to identify the K number for the fittest CHs. This brings down the cost of the function.
where f
1 denotes the Euclidean distance average maximum among nodes of their related CH, and C
s indicates the actual nodes that best fit within the krill cluster C
k. The function f
2 is used to depict the relationship between the total and starting energy of the nodes En
3, i = 1, 2…, N, found in the network and the total and presently available energy for the CH candidates in their actual round. β denotes the personally chosen constant which is used for weighing the contribution of every sub-objective. The fitness function has the distinct objective of bringing down the into-cluster separation measured between nodes and their CHs. This was quantified by f
1:f
2, which measures the effectiveness of energy found in the quantified network. According to the cost function definition, smaller values for f
1 and f
x will mean the cluster is ideal and has the optimum number of nodes. This also means the cluster has the required energy to perform all tasks that are connected to the CH. The function f
s considers path delay, average energy, and successfully transferred data.
Step 1. Set the S krill for holding K of the CHs randomly designated among the CH candidates that are suitable.
Step 2. Calculation of the path cost function for every krill
i. For every node n′ = 1, 2, …, N,
Figure out the distance d (ni, CHμ, ω) between the node ni and all the CHsCHp.
Delegate the node
En, to the CHCH
μ where in
ii. Now estimate the cost function with equality.
Step 3. Find the perfect krill for each one and further identify the best-positioned krill.
Step 4. Update the individual position in a search space.
Step 5. Repeat the steps 2 to 4 until the maximum iteration number is met.
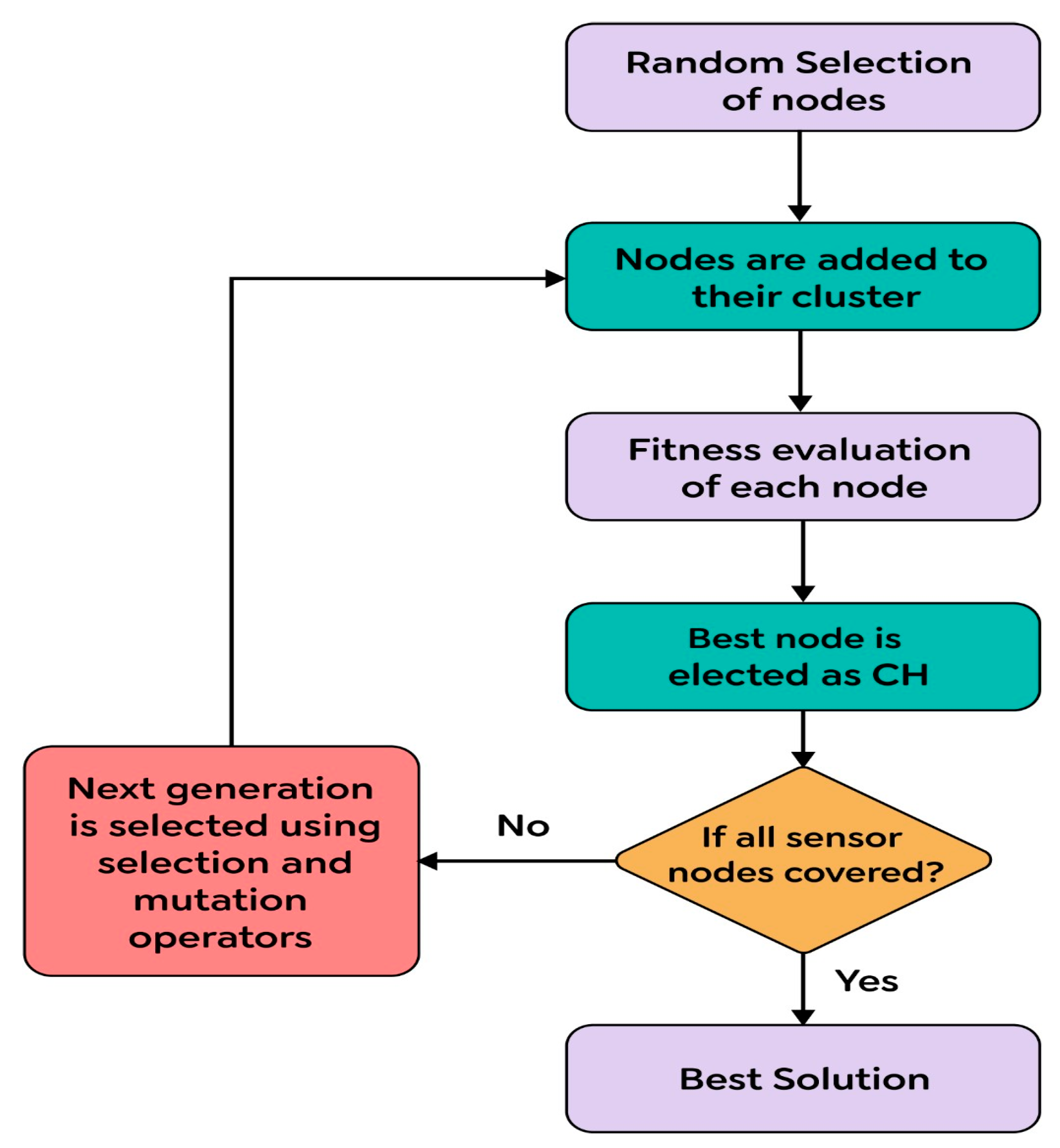
Information that consists of separate 𝔻 values for every CH to each and every node is communicated to the sensor field as soon as an optimal cluster combination is obtained by the BS. Clustering algorithms along with their process accomplished by incorporating KH into a WSN are depicted in
Figure 1.
3.3. Dual-Cluster-Head Selection
The modified krill herd optimization approach selects master cluster heads instead of cluster heads. The three components of the coordinate axis in x, y, and z are used to identify the node’s position because the deployment environment is three-dimensional and underwater.
Due to the discontinuous distribution of the nodes in the water, it is impossible to precisely map the estimated value of the aforementioned formula onto the location of the real node. The cluster node position is therefore modified as follows:
Where pk denotes the position that is closest to the actual circumstance, pix, piy, and piz are the exact values of the cluster’s components of x, y, and z, respectively, and xi(n) is the adjusted node position.
The implementation of a dynamic layered dual-cluster routing method in UWSNs based on krill herd optimization can now be said to have been accomplished with assurance. A list of these actions is as follows:
Step 1: Initializing the krill. It is necessary to establish each distinct random location in 3D space before modifying the position and projecting it onto the distribution of nodes in the water.
Step 2: Determining the fitness value. Within the clusters, the krill individual extremum and the highest adaption values are determined to determine the krill’s present position. The global extremum of the krill swarm is where the krill are.
Step 3: Observe a change and relocate.
Step 4: Updates are made to the local and global extremums, and the updated adaption value is determined.
Step 5: In order to avoid exceeding the maximum number of repeats, steps 3 and 4 should be repeated.
Step 6: The master cluster head is chosen to be the global extreme.
Step 7: To eliminate the vice-cluster head, repeat the previous procedure using the value function on the vice-cluster head.

 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}